A Data lake is a corporate repository that bridges the gap between data storage and analytics via the support of multiple formats and query engines.
The daily mood
I had the opportunity to present GitHub Actions (see my previous post) during our team call, with report on our evaluation activities and findings. This actually rose good questions and feedback.
At the same time I've been concerned, potentially complaining, about not having a clear role and acceptance when entering projects. On one hand, I still have a lot to learn before becoming fully operational. On the other hand, I had not real engagement since I started, and cannot wait for it.
There is one program which I can definitely contribute too, based on my available skills and experience: Building our internal Data lake. For some reason, this topic is pretty must resting in the background of other initiatives although it has actually been initiated 2 years ago. So that I fell empowered to make it great again ;-)

What is a Data lake
A Data lake is a single distributed data store used for Ingesting, Refining and Analyzing any kind of enterprise data at scale. Unlike a Data Warehouse, it does not natively support Data definition language (DDL). But it supports Schema-on-read and unstructured data. A Data Lake is a critical asset that requires Security and Governance.
Because of the high volume of information ingested into a Data lake, it is also a common source for traditional Machine Learning (ex. detection of financial fraud, energy network anomaly or customer churn, dynamic pricing or forecast) and modern Deep Learning (ex. voice and face recognition, analysis of medical tumor or manufacturing quality, augmented reality, GANs) use-cases.
There is obviously a common business need and strategy behind building a Data lake, which is overall to bring the organization through digital transformation, get more market or customer insight (i.e. 360-degree feedback) and eventually take smarter decisions both at executive and operational level.

It brings a few challenges from choosing the right repository till using and maintaining it.
Technology maturity
According to Confluent experts, we already reached the second main Generation of Data Lakes:
| Gen. | Approach | Storage system | Storage format | Ingest | Access | Compute |
|---|---|---|---|---|---|---|
| 1.a | In place, append-only batch operations like in Hadoop platform | Block-store i.e. SAN- arrays of 128MB sized data blocks on HDFS | Row (Positional, CSV) or Column (Parquet, Druid) formats | Sqoop, SDK and 3rd-party connectors | HCatalog, Hive, Impala | MapReduce, Tez |
| 1.b | Same as 1.a plus upfront Kafka event-hub from Streaming, Lambda and Kappa architectures | File-store i.e. direct persistence as file-level | Serializable row (JSON, Avro, Arrow) formats | Flume, SDK and 3rd-party connectors | Kafka commit log | Spark, Flink |
| 2.a | Cloud, faster-read- access, segregation of storage/compute using IaaS elements | Object-store i.e. RAID virtualization ex. S3, Azure Blob, ADLS, GCS, Ceph, Ozone. | Table formats (Presto, Delta, Iceberg, Hudi, BigTable) | Staging, SDK and 3rd-party connectors | Redshift, Athena, Snowflake, BigQuery | Serverless engine ex. Databricks, Qubole |
| 2.b | Same as 1.b & 2.a minus batch specific storage like in Confluent platform | Tiered object-store, currently only AWS S3 | Depends on the use-case | Kafka connect | Schema registry, ksqlDB | Kafka streams |
Credits: Kafka as your Data Lake, is it feasible? by Guido Schmutz
Ingestion
Like food, information gets ingested and digested, both process steps being decoupled from each other. A typical pattern for Data ingestion is the Hub-and-spoke architecture (as opposed to point-to-point), where a central server is used to run E(T)L jobs that synchronously connect to source systems in order to request and poll data which is then optionally transformed and loaded somewhere else.
Unfortunately, batch extraction is a resource-intensive operation that might slow down, freeze or even crash a source system. In order to prevent any negative impact for the business on productive applications, integration jobs are usually scheduled to run when the business is over (ex. at nights or weekends) or on vendor supported mirror (ex. distributed database replica, disaster and recovery system or snapshot).
Even more importantly, it is definitely worth checking whether your source system can handle events which could be pushed "as they come" (i.e. as a Stream) through "outbound connectivity" (ex. Webhook) to a broker system, and then collected asynchronously by the ingestion process. This method is commonly used in the financial, retail and industrial sector for real-time analysis.
Like any other architecture component, a data loader brings some kind of interface (input/output), logic (internal orchestration) and integration (external communication). Therefore, in order to enforce control on your ingestion process, a couple of basic validations should be considered:
- Source system is available (liveness) and responding (readiness)
- Source connection is authorized
- Source data exists and is readable
- Input has the expected size, encoding and format
- Target system is available (liveness) and responding (readiness)
- Target connection is authorized
- Target space exists and is writable
- Output has the expected size, encoding and format
Any error status should be exposed (ex. monitor) and handled accordingly (ex. alert).
Management
Now you want a Data lake, not a data swamp! A typical mistake is collecting as much data as possible and transform it as soon as possible. Not only this approach does not scale, but it prevents any future change right from the begining. A good initial Data lake design and user guideline are absolutely required in order to get some value out. We’ll put 5 principles together.
#1 Implement at least four zones
- Transient zone: For landing temporary data, e.g. database dumps.
- Raw zone: For collecting and retaining all versions of the data in almost original state (no model), if possible already timestamped (immutable snapshot) if possible, anonymized and partitioned, e.g. flattened records.
- Trusted zone: For cleansing, standardization, validation and modelling on the last version of the data (single version of the truth) e.g. star schema.
- Refined zone: For exposing normalized, filtered or aggregated data e.g. views to consuming downstream applications.
This allows maximal focus and flexibility for data operations from data ingestion to refinement.

Source: DZone Data Lake Governance Best Practices
We plan to allow some access the Trusted (ex. Data Analyst via Snowflake) and the Refined (ex. Business users via Tableau) zones. Later on, we may also enable some application integration (ex. via service endpoint).
#2 Design the structure of your raw zone (so that anybody can understand what's in it, and select a dataset)
- Source_system=SAP_US_5
- Extraction date=20200701
- Business object=MM_VIEW_XY
- Extraction type=FULL/DELTA
On one hand, be aware that this zone has a high impact on your sizing, since it typically contains a high redundancy, high retention time and low compression. On the other hand, the structure will help for data partitioning and selection.
#3 Store and pass logically refined results in a suitable format
As already mentioned as part of the table around "Data Lake generations" further above, there are 3 main different categories of dataset representations / storage formats:
- Row-based ex. CSV, Apache Avro
- Columnar ex. ORC, Apache Parquet
- Table-based ex. Delta, Apache Iceberg
In this section, we will take a look at those maintained by the Apache Software Foundation (ASF).
Apache Avro is a row-oriented remote procedure call (RPC) format similar to Thrift and Protocol Buffers. It supports hierarchical data and schema change via JSON metadata ("Avro schema"). Data is encoded in a compact binary format. It is a good choice for streams of data-in-motion that needs to be exchanged as a serialized object (ex. via an Event-Broker).

Apache Parquet is a column-oriented storage format similar to Apache ORC. It provides efficient data compression and encoding schemes with optimization for handling wide bulk tables ("write once read many"). It is a good choice for data-at-rest which needs to be filtered and aggregated efficiently (ex. via an additional query engine like Presto or Spark SQL).
Apache Iceberg is a table-oriented storage format similar to what you can achieve with Parquet, except that records are already presented as table, i.e. in a user-friendly way. It relies on an external meta-store to support schema evolution and is well integrated in the popular compute engine Apache Spark. It is a good choice if the storage is used both for efficient aggregations and history access.
Note: There are also formats that I will qualify of "hybrid" like for example Apache Arrow, which might offer the best of all worlds for supporting data analytics applications both a in-memory columnar format and a gRPC serialization protocol ("Arrow Flight"). Dremio is probably the most popular Data Lake solution based on Apache Arrow.
#4 Refine your data by use-case
In terms of use-case, you should ask yourself not only what are the source systems, but also who is the consumer, what is the downstream application, what kind of delivery stream is required, how actual, authentic and aggregated the data should be etc.
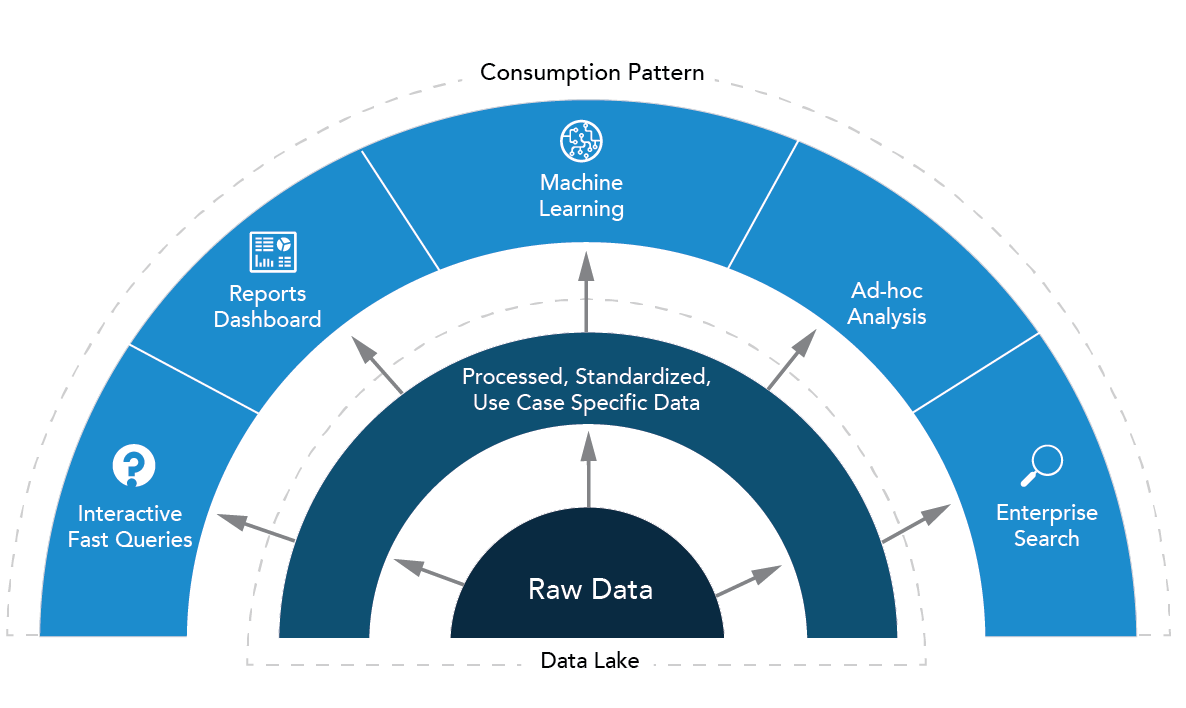
Source: CloudTP Data lake Consumption Patterns
Unlike for a Data Warehouse, the process of refinement is much more than just data normalization. It should reconciliate separately stored entities, enrich records stepwise with all information and prescriptions relevant for the end-consumer.
#5 Automate as much as you can
Remember you are building a growing system, able to process a huge amount of data from many sources, and to potentially serve use-cases for your entire business. Forget about contracting an external consultant who is likely to disappear after coding a big monolith script running somewhere, somehow... This might be ok for a "quick win" but not for the long-term. Instead, you should try to standardize as much as possible your data promotion pipeline from source to refinement. Here is a list of high-level requirements:
- a hardware infrastructure dedicated to your integration layer (ex. IaaS)
- an agile team (ex. Scrum) of data engineers
- a modular application supporting change management
- a product owner (PO)
- a well-defined process for Software-Development-LifeCycle (SDLC)
- operational reliability and maintenance (SLA)
Build your own integration platform or select a vendor product if you can afford it, it typically ships with a solid toolkit for designing and executing Data integration flows based on graphical pipes-and-filters supporting ETL patterns, a job scheduler for planning and orchestrating pipelines, an operational console for user administration and monitoring. We use Talend for development and Kubernetes for operations. Plus, you may have the option to extend to Data Quality (ex. a portal to define standardization rules, match your records, remove duplicates and reconciliate errors) or Advanced Analytics (ex. self-service BI). In case your data source/target is in the Cloud, then it definitely makes sense to run your integration and analysis processes in the Cloud as well.
Security
Different Data lake zones will not only allow different functions but also different access rules.
- Encryption at storage level ("at rest") - storage providers automatically generate customer keys
- Encryption at network level ("in motion") including SSL, ACL and CIDR block restrictions
- Authorization at application level including RBAC and MFA-tokens
Note that AWS Lake Formation is a managed service that allows for adopting proper security settings and access policies from the ground up.
Comments
Post a Comment