Curve fitting is probably one of the key enabler for data analysis. It helps understanding historical datasets, recognize patterns and take action.
The weekly mood
I took a couple of days off to visit my parents. I had not seen them for the last 7 months, not only because of the 8 hours drive required to reach their place, but also because of the sanity restrictions introduced with COVID-19.
Given some increasing expectations from my job, I found that moving my blogging activity from posts that used to come out almost on a daily basis would be more realistic on a weekly basis.
Following to the
Garmin's outage that happened during the week-end, I shortly came to think again about my Strava segment effort analysis topic. Although I was quite satisfied about the status of my
previous post, I had to admit that comparing segment efforts "only" through average power by average grade is probably not enough for creating a performance indicator.
Performance range
My first concern was to analyse the distribution of segment efforts for all a ailable data or "gloabl dataset". Using a
boxplot diagram (ex. from
Seaborn module) tell us the min, max, mean, first (i.e. 25%) and third (i.e. 75%) quartiles, whiskers (i.e. away values to include) and outliers (i.e. away values to exclude).
import matplotlib.pyplot as plt
import seaborn as sns
plt.title("Overall distribution analysis")
ax = sns.boxplot(x='avg_grade',y='avg_power',data=df.round({'avg_grade': 0}))
ax.set_xticklabels(ax.get_xticklabels(),rotation=90)
plt.show()
The segment effort by elevation grade follows a nice logistic curve, but we'll come back to this point later. It was clear to me that I will not get a power datapoint for any possible grade. But as we can see, the range of values (i.e. height of the boxes) is broader at low grade than at high grade. There are 3 main reasons for that:
- If not insane, your training roads will "naturally" include more segments with low grade
- You might "let it roll" at low grade without loosing much speed
- Energy transfer is a lot more effective for the same effort at high grade
Effort duration
It takes a lot more for the legs to deliver an average of 200 watts for 10 minutes (ex. climbing over a hill) than the same average for 1 minutes (ex. riding against the wind) of 10 seconds (ex. sprinting to a road sign). Since I have no clear idea of my
VO2 max or
lactate thresholds, and usually do not record my heart rate when riding, I had to find another intensity indicator. Assuming that segment difficulties and efforts are fairly constant for each given segment, we may look at the segment effort duration.To keep it simple, we'll separate segment efforts between
anaerobic and
aerobic exercise given the largely agreed treshhold of "roughly 2 minutes", after which the metabolism relies more on oxygen than on glucose for producing energy. Finally, in case multiple power measures were recorded for a given grade, we might keep the best one to dress conclusions.
# split dataset in 2 categories of effort duration
df_anaerobic = df[(df.duration < datetime.timedelta(minutes=2))]
df_aerobic = df[(df.duration >= datetime.timedelta(minutes=2))]
# keep best perf in case different exist for same seg or avg_grade
df_anaerobic = df_anaerobic.groupby(['avg_grade'])['avg_power'].agg('max').reset_index()
df_aerobic = df_aerobic.groupby(['avg_grade'])['avg_power'].agg('max').reset_index()
From a statistical perspective, we get slightly more consistency, especially for aerobic efforts where the boxes height is half smaller. The logistic curve also flattens a bit slower given that the x domain is largher. From a medical perspective, anaerobic efforts introduce a further energy system for efforts under 30 seconds, which rely more on immediate
Adenosine Triphosphate and
Phosphocreatine (ATP-PC) than on glucose. This would probably help at getting even more consistency.
Curve fitting
Our former application used to assume that segment efforts behave like a
linear function of the elevation grade, which might be acceptable for our small domain of observation (ex. -5 to 25%). Well, we also assume the ground to be almost flat under our feet ;-) A first degree polynom is actually a good starting point for
curve fitting, i.e. for calculating a best-fit function depending on available data points. At the end we are looking for the nearest curve by comparing the cumulated distance to the points, also refered to as the
Total Sum of Squares (TSS), because it mathematically eliminates negative signs.
where
- yi = the y value of a data point at index i (there might be multiple ones by x values)
{\displaystyle {\bar {y}}}  = the y value of the mean curve
= the y value of the mean curve
Provided that you know the mean parameters, it is fairly easy to verify TSS value through a user defined function in Python, or use an existing module like for example
Scikit-learn mean_squared error.
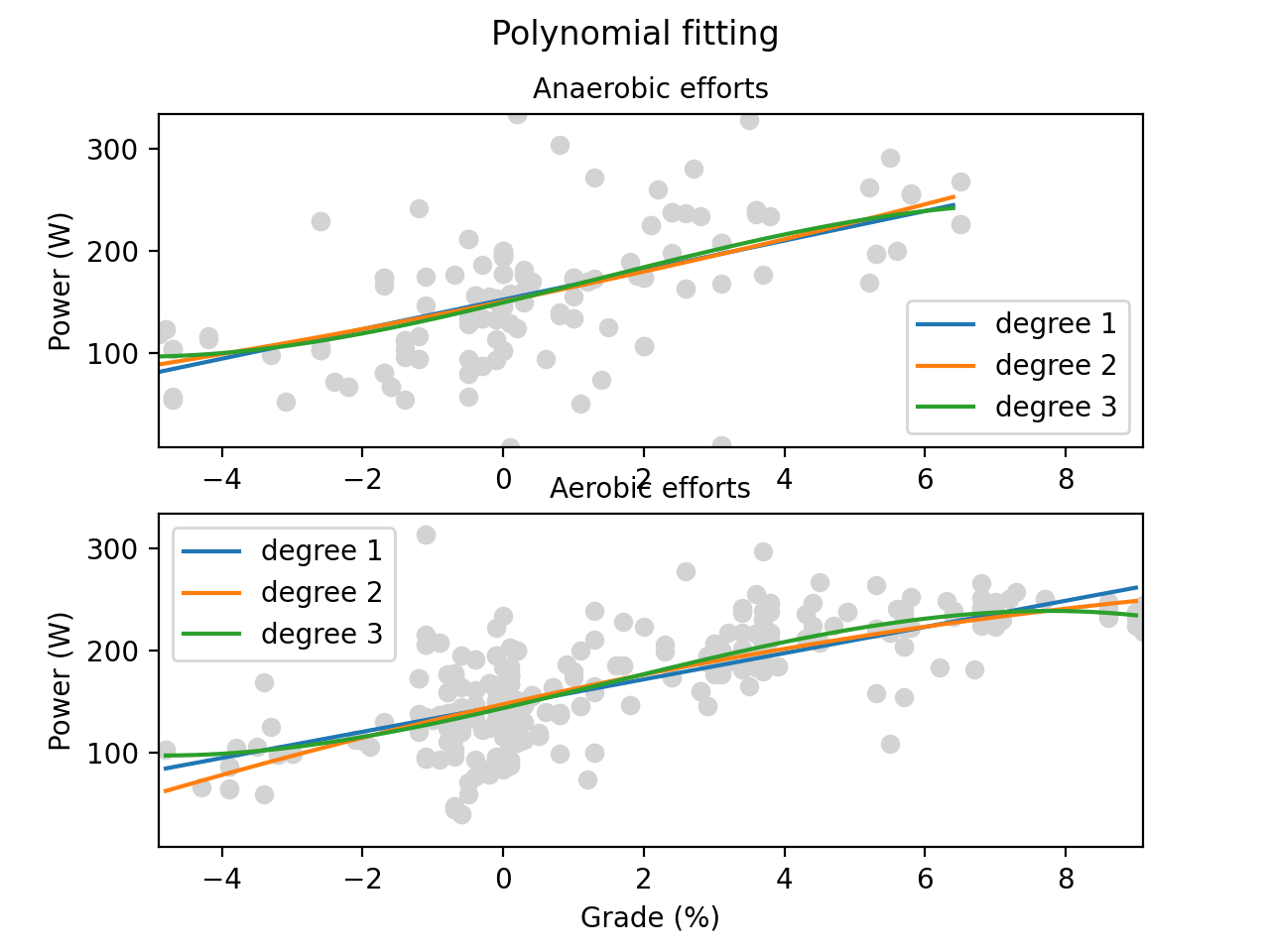
Polynomial fitting
We'll use
Numerical Python (NumPy) for automatically calculating polynomial fitting.
import numpy as np
import numpy.polynomial.polynomial as poly
# anaerobic: bars
a[0].set_title("Anaerobic efforts", fontsize=10)
a[0].bar(df_anaerobic['avg_grade'],df_anaerobic['avg_power'], 0.2, alpha=0.5)
df_x_np = df_anaerobic['avg_grade'].to_numpy()
df_y_np = df_anaerobic['avg_power'].to_numpy()
# anaerobic: decimal fit
for degree in range(1, 3, 1):
coefs = poly.polyfit(df_x_np, df_y_np, degree)
x = np.arange(df_x_np.min(), df_x_np.max(), 0.1)
df_f_np = poly.polyval(x, coefs)
a[0].plot(x, df_f_np, label="degree " + str(degree))
# anaerobic: logarithmic fit
x = df_x_np - df_x_np.min() + 1
coefs = poly.polyfit(np.log(x), df_y_np, 1)
df_f_np = poly.polyval(np.log(x), coefs)
a[0].plot(df_x_np, df_f_np, 'y', label="log")

Here we use Matplotlib
subplot feature for superimposing multiple diagrams inside one single figure. It becomes clear that polynomial functions somehow fit with the mass, but not well enough for building a reliable statistical model, even when increasing the polynomial degree.
Non polynomial fitting
In fact, riding efforts behave like a
gaussian function, which means we may produce our best effort at most convenient grade range, not above and not below. However, we may ignore both climbing and descending "walls" for a relevant analysis, and consider the left part of the gaussian only. As already discussed at distribution analysis, that is a
logistic function (aka.
error function) or sigmoid (aka. "s-curve") which is defined as follow:
Implementing it is straight-forward in Python, provided that you know the 3 parameters. On the other hand, guessing or calculating those 3 parameters is quite tedious, as explained in
this article. By chance, we can use
SciPy library to achieve just that.
from scipy.optimize import curve_fit
# generic logistic function as per https://stackoverflow.com/questions/60160803/scipy-optimize-curve-fit-for-logistic-function
def logifunc(x, A, x0, k, off):
return A / (1 + np.exp( -k * (x - x0) ) ) + off
# parameter calculation
popt, pcov = curve_fit(logifunc, df_x_np, df_y_np, p0=[df_y_np.max() - df_y_np.min(), 0, 0.1, df_y_np.min()])
a[0].plot(x_data, logifunc(x_data, *popt), 'r-', label='logistic')
Note that we also included a logarithmic function as part of the diagram, for the sake of analysis completion.
x = df_x_np - df_x_np.min() + 1
coefs = poly.polyfit(np.log(x), df_y_np, 1)
df_f_np = poly.polyval(np.log(x), coefs)
a[0].plot(df_x_np, df_f_np, 'y', label="logarithmic")
Data Science
Another possible approach to this problem is to skip curve fitting and directly generate a statistical model using libraries like
Statsmodel and
SciKit-Learn (which are actually based on what we have done so far). The huge advantage of a model is to support multi-dimensional domains, i.e. functions that you cannot represent with only 2 axis. There is also a bit more theory behind, like for ex.
Probability Density Function /
Probability Distribution Fitting (PDF).
Take away
Based on a real world use-case, we now better understand the need, complexity and methods for describing training datasets and generate scoring parameters.
Later, we might use the parameters for building a
Machine Learning (ML) model, e.g. for classification (ex. does this new performance belong upon or below expectation?) or regression (ex. which effort to expect for a new segment?) purpose.
Source code








Comments
Post a Comment