Data Governance is such a wide topic in theory, that most people are confused about which practical approach to choose regarding their Data Lake.
The weekly mood
I finally have the warm feeling that I well integrated the department which I joined nearly half a year ago. Why such a long time for such a simple goal? Well, if I had to retrospect on this development, I would split it into the following under-estimated phases:
- Observation
- Fail-fast Exploration
- Deep-dive Immersion
- Go Mainstream
I was definitely not as easy as I expected given my background and motivation. I was glad to have the chance to touch-point on various topics from DevOps to API and Big Data. It was much less pleasant to partly have to wait for months until I got access to the systems and services I needed. Obviously there were some social restrictions related to COVID-19 and time-zones. To finish with, I not only needed to get used to our workflows, but confident with our goals, which also asked for some normal adaptation time.
Let's now follow-up with a series of articles around the Data Lake. In part 1, I explained what it is and how to architect it. Now let's have a look at how to govern it.
What is Data Governance
Electronical Information Governance aka. Data Governance is the general practice of linking records of a storage system (ex. a Data Lake) with transparent processes and responsibilities. The term Governance is profoundly anchored in Information Technology (IT). It is derived from the Greek verb "kubernaein" which means "to steer", and reveals our natural effort to subordinate all kinds of things and assets that might represent a risk in case they are not observed and controlled. In a corporate context for example, IT Governance defines and maintains policies that allow for People, Process and Technology to drive better Business outcomes.
First Data Governance concerns emerged in the early 1990s from the new practice of building Data Warehouses (DW), which one involved the replication of significant amounts of Data from Host systems aka. IBM Mainframe. Data Governance then moved into the background of Web Service Governance in the early 2000s, itself not only decoupling Business Applications from underlying Systems, but also standardising interfaces and policies as required by some newly establishing industrial conformity around Governance, risk management and compliance (GRC).
With the rise of Big data and Cloud computing technologies in the early 2010s, three major risks were eventually assessed:
- Regulatory compliance: Data not only became a new enabler for globalisation aka. Data Economy as acted out by the Big Five, but also financial Corruption and Tax Fraud. New policies had to be enforced across all regions and economical sectors.
- Information breach and publication: The number and severity of data leaks grew significantly. For example, governments were primarily targeted and blamed through the Diplomatic cables (2010, Wikileaks, 1.7 GiB) and the Panama papers (2016, Süddeutsche Zeitung, 2.6 GiB).
- Unmanageable Data Lake aka. Data Swamp: With the shift of focus from centralised control to a shared model to respond to the changing dynamics of information management, it became difficult to identify and find assets that are supposed to be auditable and deliver insights.
Since only the first point is mandatory, hard to implement by organisations and difficult to control by federal instances, the budget and commitment assigned to Data Governance initiatives is usually kept relatively low. Indeed, like for other strategical and support processes of a core business, there is almost no limit in possible spending, no direct return and no clear estimation of the cost of not taking action.
Governance strategy
First and foremost, some authority is required to bring Data Governance to the agenda of top-priorities in an organisation, typically a Chief Data Officer (CDO).
Then, creating a high-level documentation of (if possible, all) information processes is a mandatory, yet unpleasant and ephemeral step to more data understanding, guidance and automation.

Source: Active Navigation - Information Governance Maturity Model
Finally, a culture that is transparent, supportive and collaborative is recommended by the book Non-invasive Data Governance by Robert S. Seiner (2014).
Defining Metadata
A native part of Data Governance is Metadata management. In a nutshell, Metadata is Any Data about Data, and is often referred to as the "navigation system" of a Data lake.
- Whom does this dataset belong to and what's in it? You basically need metadata to search for information, describe and process it whatever the context.
- Can this dataset be shared with other departments? It is obvious for some type of data (ex. your employee's payment slip) but not for all (ex. patient health records).
According to Ralph Kimball there are 3 main kinds of metadata:
- Technical metadata describes internal system (ex. file name, date, owner, size) and access properties (ex. source, format, schema, DDL). It might be automatically extracted from source or inferred.
- Business metadata covers objective (ex. glossary definitions, data owner in the form of organizational unit and contact e-mail) and subjective information (ex. sensitivity, change frequency, compliance-level, quality, trust-factor, review scores and comments). It is mainly a manual input except when using smart processing (ex. data-mining and semantical analysis).
- Process metadata covers the management of life-cycle and definition of business rules or regulatory policies. A typical use-case is data protection and retention. It is the most dynamical path to data governance automation.
Using Metadata
Except from the CDO, there are typically 4 personas interested by Metadata:
- Data consumers want to know where the data is coming from (backward or lineage analysis)
- Data owners want to know how their data is used (forward or impact analysis)
- Data scientists want to figure out how to better mine the data (semantic analysis)
- Data analysts want to verify the content and quality of the data (compliance analysis)
Managing Metadata
We'll distinguish 5 different activities around Metadata, from the most technical to the most business related:
- Discover: Metadata all starts with an access to the data, for example a connector. Different kinds of information is collected.
- Descriptions from source systems ex. file sizes and database information schema. This is Technical Metadata.
- Relevant extractions of source objects ex. hundred last updated records. This is Sample Data.
- Persist
- Technical Metadata is converted into a common format that builds the reference model of a System of records, stored and indexed for example inside a relational or graph database. This metadata cache is called a Metastore.
- Sample Data might get written as a raw blob of the previous repository, or into a different one that better supports data access and data protection. It is called a Data Catalog and might be used both internally (in support of Enterprise Search) or externally (embedded into a Data Marketplace).
- Process
- Technical Metadata stitching focuses on direct correlations and linkage, with the typical goal to represent a Lineage graph via a UI.
- Sample data profiling focuses on statistical measures and semantics, with the typical goal to analyse Data quality (ex. percentage of empty records) and Data mining (ex. probability of a column to match the category PII, therefore candidate to automatical mask/anonymize).
- Enhance: Beside Metadata management automation, it should be possible to derive both interactive and automatic Business processes and Applications from Metadata, for example
- Import of a Business Glossary (ex. "customer feedback" is a business entity representing any positive or negative signal that is directly or indirectly addressed to our organisation...) from an external Authoring application or collaboration workflow.
- User-input in the form of Tagging (ex. this column or record is deprecated) and Authoring (ex. in the future, this flag should be triggering an escalation process).
- Trigger Notifications to downstream applications, enabling Metadata-driven Integration and Governance.
Metadata tools
In this section, we will introduce a few Open-Source projects that are supporting Metadata management.
- Push-based systems for cumputing
- Apache Hive HCatalog is a low-level API to store and access Metadata stored in Hive Metastore. The service was originally created for the vanilla distribution of the Apache Hadoop platform. It is very popular and integrates into various storage and compute technologies, so that even major Platform providers are complying with it for example AWS Glue Catalog, Databricks Metastore and some Snowflake integration. Bottom-line: Consider it as the current standard for compute activities.
- Apache Atlas (by Hortonworks) is an alternative low-level API and Metastore which extends to a number of sub-projects. Unfortunately the main project used to lack development support while still incubating, as compared to its relatively large consortium. I experienced customers from the financial sector who were much valuing its production-ready integration with Apache Ranger for tag-based-security, whereas IBM actually pushed on compliance features (in order to get patent for a very first Open Metadata standard, as finally achieved with the LFAI Egeria project). Bottom-line: Do not invest too much in.
- LFAI Marquez (by WeWork) is a much younger project which provides a high-level API. It is very easy to use and I found only a few unexpected behaviors such as having to choose the type of source from a list of limited options (ex. choose POSTGRESQL for Snowflake). The Web-UI looks pretty, but currently does not include any user-authentication, and the lineage graph feature did not extend to multiple jobs for me. What I am especially excited about is some operational status displayed as part of the lineage information, answering questions such as did my staging data succeed or failed to load for the last 10 executions. Bottom-line: Monitor it closely.
- Pull-based systems for consumption
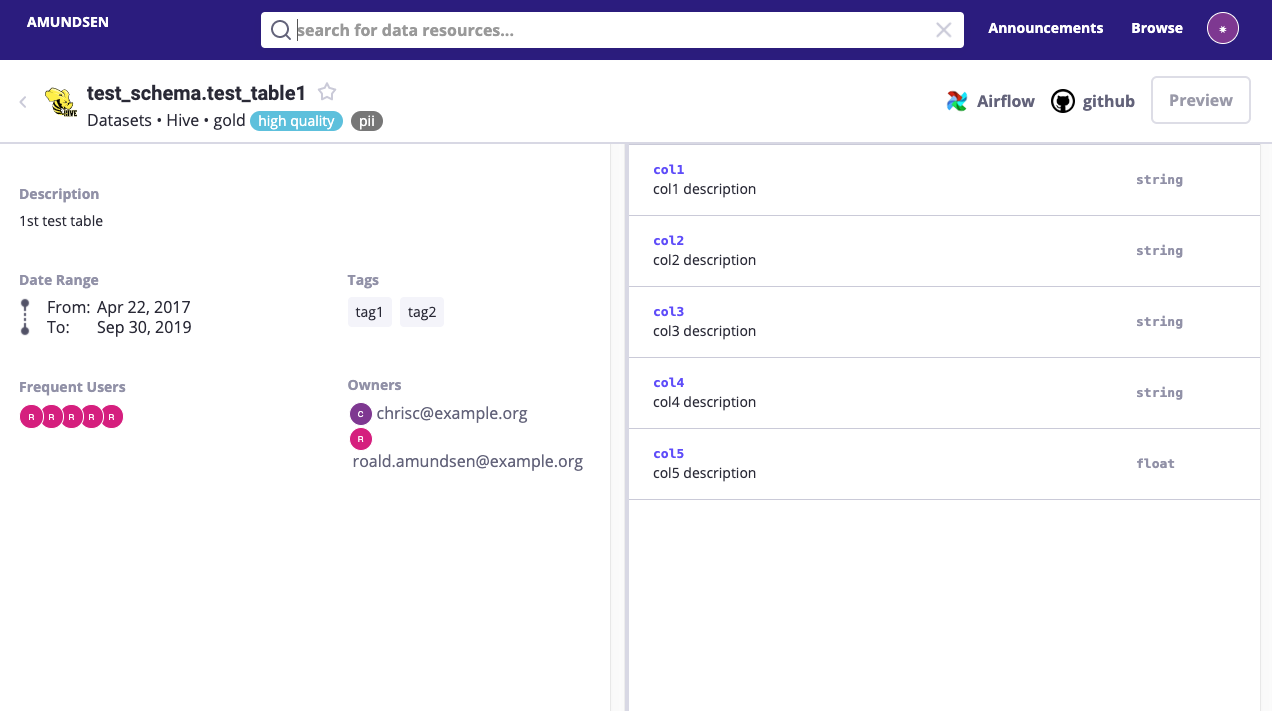
- LFAI Amundsen (by Lyft) and Netflix Metacat are both Data Discovery tools. On one hand, they provide crawlers able to automatically collect Technical Metadata and Data Samples from analytical databases. On the other hand, they provide a user-friendly Web-UI to easily search and access information including semantics. I would advise not to overuse the crawler pattern against your source systems, instead to synchronize information from your central metastore, like it was done for example at ING and explained in this article.
Bottom-line: Great for Metadata consumption through Business users.

Research
To finish with, there are a number of recent papers showing the importance, complexity and actually of Metadata handling:
- Metadata as a Service (2015)
- Managing Google’s data lake (2016)
- A Data Context Service (2017)
- Metadata Systems for Data Lakes (2019)
Comments
Post a Comment